[논문 링크]
https://arxiv.org/pdf/2005.14165.pdf
이번엔 GPT-3 논문에 대해서 리뷰 해보고자 한다. 이미 GPT라는 모델은 굉장히 유명해졌으며, 어떻게 보면 전 세계적으로 AI라는 분야를 널리 알린 논문이 아닐까 생각한다.
GPT 논문 시리즈는 처음부터 하나씩 읽어보면 좋은데, GPT-3는 이전 논문들과 어떤 차이 점이 있는 지를 생각해보면서 읽어보면 좋다.
이 논문을 읽은 후기를 먼저 말씀 드리자면, 테크니컬한 접근보다 리소스를 키운 접근 방법으로 모델의 성능을 향상 시킨 것이 주된 내용인 것 같았다.
키워드는 가볍게 참고만 하자.
Keyword: Zero-shot, One-shot, Few-shot learning
Abstract
- NLP 모델이 많이 발전했으나 여전히 task-specific의 재학습이 필요하며, 이 과정에서 task에 맞는 학습 데이터들이 필요하다.
- fine-tuning에 대한 한계점 언급
- 언어 모델의 사이즈를 키워서 task-agnostic 모델을 개발
- few-shot 모델 성능도 향상
- 175B params의 GPT-3 개발
- 더불어 인간이 작성한 기사와 유사한 수준의 기사 샘플 등을 생성할 수 있음 → 사회적 영향에 대한 논의
Introduction
- NLP 모델이 좋은 성능을 보이고 있지만, task-agnostic한 모델이기 때문에 task-specific한 dataset으로 fine-tuning이 필요함
- task-agnositic이란, 특정 task의 사전 지식이 없음을 의미
- Fine-tuning은 여러모로 비효율적
- 새로운 task에 해당하는 대규모 데이터셋이 필요하다? → 비효율적이며, dataset 구축에도 cost가 높다.
- 큰 모델을 작은 데이터셋의 분포로 학습시키면, 오히려 잘못된 correlation을 학습할 가능성이 높다.
- 인간은 특정 task에 대해서 많은 양의 학습 데이터를 필요로 하지 않는다.
⇒ 이런 문제점을 개선하기 위해 ‘meta learning’, ‘in-context learning’이 등장하기 시작했다.

하지만 이런 approach도 fine-tuning의 성능을 따라가지 못했다.
NLP 모델의 또 다른 트렌드는 transformer 기반 모델의 parameter를 증가 시키는 것이다.
- parameter의 수를 증가시킬 때마다 성능이 향상되는 것을 확인할 수 있었고, 많은 downstream task에서도 improvement를 관찰할 수 있었다.
- in-context learning은 model의 parameter 내에서 skill과 task를 배우기 때문에 scale이 커지면 커질수록 더 좋은 성능을 가진다는 것은 plausible하다.
- 여기서 model의 parameter 내에서, 라는 말의 뜻은 parameter의 변화 없이 모델 그 자체를 가지고 어떻게 활용할 것인 지에 대한 의미인 것으로 보인다.
여기서 175B의 GPT-3 모델을 개발했으며 3가지의 조건에서 모델을 평가한다.
- few-shot learning
- 일반적으로 10-100개 사이로 context window에 맞는 수준의 in-context learning
- one-shot learning
- task에 대해서 하나의 샘플만 허용
- zero-shot learning
- 샘플은 주어지지 않은 채로, task에 대한 설명만 제시

- 더 많은 parameter를 가지고 있을수록, 더 성능이 좋은 것을 확인할 수 있다.
- 또한, parameter가 더 많을수록 one-shot / few-shot에 대한 성능 향상 폭이 큰 것을 확인할 수 있다.
- 특정 task에 대해서는 SOTA와 비슷하거나 그보다 더 향상된 성능을 확인할 수 있었다.
- 하지만 ANLI, RACE, QuAC와 같은 task에서는 아직 어려움을 겪고 있다.
- ANLI : 자연어 추론 / RACE : 독해 / QuAC : Question _ Answering

또한, ‘data contamination’에 대한 문제도 겪었다.
- 일반적으로 crawling을 통해 web-scale의 dataset을 구축하다 보니, test dataset이 이미 노출되어 있는 경우 등의 문제가 발생한다.
- data contamination이 GPT-3에 큰 영향을 주지는 않지만, 일부 데이터 셋들이 inflating result를 유도하는 것을 확인
- 따라서 이 논문에서 systematic tools에 대한 개선된 방안을 제시한다.
마지막으로, GPT-3의 bias, fariness, broader societal impacts에 대한 이야기를 다루고자 한다.
2. Approach
기본 pre-training approach는 GPT-2와 유사하지만, model / dataset size / length of training 등을 scaling up
In-context learning을 사용하는 방식도 GPT-2와 유사하지만, 다른 setting들이 존재하기 때문에 해당 section에서 자세하게 define

- Fine-Tuning (FT)
- 원하는 task에 맞는 specific supervised dataset으로 pre-trained model의 weight를 update
- 모든 task마다 새로운 large dataset이 필요하다는 점 / poor generalization out-of-distribution 등의 문제점을 가지고 있다.
- 여기서는 task-agnostic performance에 대해 초점을 맞추고 있으므로 GPT-3를 fine-tuning하지 않을 예정이지만, fine-tuning이 불가능하진 않다.
- Few-Shot (FS)
- weight의 update없이, conditioning으로 task에 대한 few demonstrations을 inference 때 제공하는 방식이다.
- 일반적으로 10-100개 사이의 example을 제시한다.
- task-specific한 data가 거의 필요 없으며 narrow distribution을 학습할 잠재 위험성도 줄어든다.
- narrow distribution : large distribution이 narrow fine-tuning dataset에 의해 학습되는 것
- 하지만 fine-tuning된 다른 SOTA 모델들보다 성능이 좋지 않으며, 여전히 task-specific data가 필요하다는 것이 단점
- weight의 update없이, conditioning으로 task에 대한 few demonstrations을 inference 때 제공하는 방식이다.
- One-shot (1S)
- few shot과 구별되는 점은 단 1개의 sample만을 제공
- 인간의 소통 방식과 유사하기 때문에 따로 구별
- Zero-shot (0S)
- one-shot에서 example을 주지 않은 것과 동일 → 즉, task에 대한 instruction만 제공
- 매우 편리하고 robustness도 보장될 수 있으나, challenging한 문제
- task에 대한 설명이 ambiguous하면 오히려 더 안 좋은 결과 도출
- 인간이 task를 수행하는 것과 가장 가까운 형태의 learning
2.1 Model and Architectures

- GPT-2와 같은 architecture & model을 사용하지만, initialization, pre-normalization, reversible tokenization 등의 modification을 포함하고 있다.
- 또한 Sparse Transformer에서 사용된 것과 비슷한 dense and locally banded sparse attention patterns을 사용한다.
- token의 일부만 attention을 사용하는 기법으로 알고 있는데, 계산 효율성 때문에 이것을 사용하는건가?
- reversible tokenization : tokenization 과정을 역으로 복원할 수 있는 방법을 의미
- token을 원래 text로 정확하게 복원할 수 있어야 데이터의 원본 내용과 형태를 보존할 수 있다.
- 매우 정교한 text를 생성하기 위해서 모델이 생성한 결과물을 자연어로 변화하는 과정에서 사용할 수 있다.
- 정확한 평가를 위해 필요하다.
- 또한 Sparse Transformer에서 사용된 것과 비슷한 dense and locally banded sparse attention patterns을 사용한다.

- model size에 따른 ML performance를 연구하기 위해 8개의 다른 크기의 모델들을 훈련
- 이전 연구에서 충분한 training data와 validation loss의 scaling은 모델 크기와 관련된 함수로 approximate 될 수 있음을 언급
- 따라서 이 가설에 대한 test를 위해 table 2.1처럼 model size 별로 훈련
- d_{model} : 각 bottleneck layer에 있는 units의 개수
- feedforward layer는 항상 bottleneck layer 크기의 4배를 갖는다.
- 각 hyperparameter는 computational efficiecny와 GPU에서의 load balancing을 고려
2.2 Training Dataset
언어 모델을 위한 dataset은 이미 1조 개에 달하는 words로 구성된 dataset이 있을 만큼 충분히 크게 구성되어 있으며 이는 우리 모델을 훈련하기 충분한 크기이다.
또한, 동일한 sequence를 2번 update하지 않고도 훈련이 가능하다.
하지만 이렇게 큰 dataset, Common Crawl은 unfiltered / lightly filtered 이므로 정제된 다른 dataset들보다 퀄리티가 낮다. 따라서 dataset의 퀄리티를 높이기 위해 다음 3가지 step을 수행한다.
- high-quality reference corpora 수준의 common crawl dataset을 사용한다.
- WebText를 high-quality documents와 유사하다는 가정하에서 classifier를 통해 raw common crawl과 분리하도록 수
- document 수준에서 fuzzy deduplication (중복 제거)를 수행한다.
- 이는 redundancy (불필요한 중복)을 방지하고 overfitting을 정확하게 측정하기 위한 validation set을 확보할 수 있다.
- 중복 제거를 하기 위해서, 특정 document가 다른 document와 highly overlap되어 있을 때 해당 문서를 제거하는 방식으로 진행
- 평균 10%정도 dataset이 줄어드는 효과
- 잘 알려진 high-quality reference corpora를 CommonCrawl을 augment하기 위해 더해줄 수 있으며, 이는 diversity를 증가 시킨다.
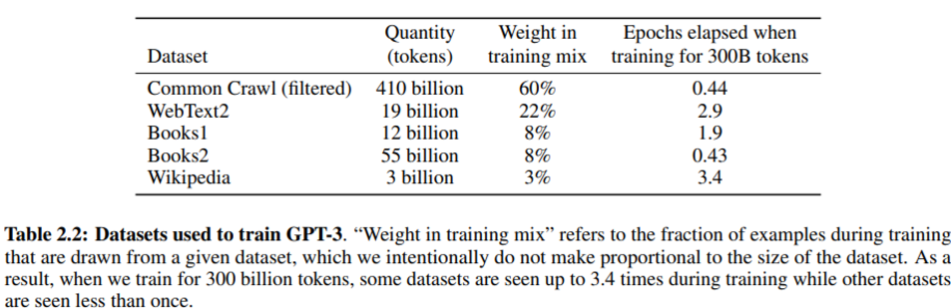
최종적으로 GPT-3를 training하기 위한 dataset들이다.
training동안, dataset들은 dataset들의 크기에 비례하여 sampling되지 않는다. 오히려 우리가 high-quality라고 보는 dataset들이 더 자주 sampling되어지며, 이는 high-quality training data를 위해 조금의 overfitting을 허락하는 방식이다.
- Common Crawl, Books2는 1번 이하로 sampling
마지막으로, 이렇게 큰 언어 모델을 학습 시킬 때, test set이 사전 학습 도중에 노출되는 등의 문제 때문에 downstream task를 정확하게 파악하지 못하는 contamination 문제가 발생한다.
안타깝게도 해당 문제를 해결하기 위해 retraining하기엔 training cost가 너무 컸으므로, 일부 문제를 무시하고 학습을 진행했으며 이에 대한 문제는 section 4에서 더 자세히 다룰 예정이다.
2.3 Training process
- 일반적으로 large models은 larger batch size를 가지며 smaller learning rate을 가진다.
- gradient noise scale을 훈련 과정에서 사용하여, batch size에 대한 선택을 할 때 사용
- memory를 다 쓰지 않으면서 모델을 훈련하기 위해, mixture of model parallelism을 사용한다.
2.4 Evaluation
- Few-shot learning
- training set에서 K개의 example을 사용하여 평가
- K는 context window의 범위 안이라면 어떤 값이든 가능하며, 일반적으로 10-100개를 사용
- K가 크면 클수록 좋지만, 반드시 그런 것은 아니기 때문에 가장 좋은 K개의 값을 찾아서 test 실행
- binary classification에서 option에 더 의미 있는 (0,1 보다는 true / false) 옵션을 부여하여 multiple choice처럼 처리
3. Results

- 학습을 효율적으로 진행했을 때, performance는 model parameter의 개수와 ‘power-law’를 따른다.
- power-law : 2개의 변수가 있을 때, 한 개의 변수를 다른 한 개의 변수에 대한 함수로 나타낼 수 있는 관계 → 여기서는 거듭 제곱으로 나오더라.
3.1 Language Modeling, Cloze, and Completion Tasks
이 부분에서는 NLP 분야의 전통적인 task에 대한 평가를 진행
[3.1.1 Language Modeling]
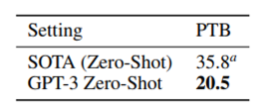
- 문장의 일부를 바탕으로 다음 단어를 예측하는 작업
- Penn Tree Bank (PTB) data에 대해 기존 zero-shot SOTA보다 성능이 좋음.
- PTB dataset : Language modeling을 평가하고 비교하기 위한 dataset
[3.1.2 LAMBADA]

- 문장의 마지막 단어를 예측
- 대부분 소설과 이야기에서 추출된 문장들이며, long-term memory와 context에 민감한 작업
- 175B 기준으로 어떤 learning 방법이든 SOTA보다 성능이 좋음.

[3.1.3 HellaSwag]
- 가장 알맞은 문장을 고르는 task
- fine-tuning한 SOTA를 능가하지는 못했다.
[3.1.4 StoryCloze]
- 다섯 문장의 긴 글을 끝맺기 가장 적절한 문장을 고르기
- SOTA를 뛰어 넘지 못했지만, 기존 zero-shot의 성능을 10% 이상 향상시켰다.
3.2 Closed Book Question Answering
폭넓은 사실 기반의 지식에 답변을 할 수 있는 지에 대해 측정
- NaturalQS : fine-grained 지식을 요구하는 task
- WebQS
- TriviaQA

- TriviaQA : 기존 fine-tuning의 모델들을 능가하는 performance
- NaturalQS : fine-grained 지식을 요구하는 task로 GPT-3의 학습 능력을 측정하기에 적절하지 않았다고 분석
- WebQS : GPT-3에게 WebQS의 질문들은 out-of-distribution이었을 것으로 추정
- free-base 기반 QA
3.3 Translation

- 93% English + 7% other languages
- 일부 translation task에서 SOTA보다 더 좋은 성능을 보임
- 데이터 셋에 일부 포함된 다른 언어들에 대해서 어떻게 이게 가능했을까? 약간의 naive한 생각이라도 들어보고 싶음.
3.4 Winograd-Style Tasks

- 대명사가 무엇을 지칭하는 지 맞추는 task
- 성능은 좋지만, SOTA를 능가하진 않는다.
- 모델의 크기가 커질 수록 성능이 향상하긴 함
3.5 Common Sense Reasoning

- 상식 추론 문제이며, 물리학 / 3-9학년 수준의 과학 시험 문제 / OpenBookQA 등에서 모델의 성능이 커지는 만큼 성능이 향상되는 것을 확인할 수 있다.
- PIQA를 제외하고 여전히 SOTA를 능가하지는 못하는 모습
이 후에 대한 실험은 쭉 살펴보길 바란다. 내가 참고했던 블로그 링크를 첨부해보겠다.
https://littlefoxdiary.tistory.com/44
[논문리뷰] GPT3 - Language Models are Few-Shot Learners
오픈 AI GPT 시리즈의 세 번째 논문이 공개되었씁니다!!!! GPT1 - Improving Language Understanding by Generative Pre-Training GPT2 - Language Models are Unsupervised Multitask Learners GPT3 - Language Models are Few-Shot Learners 2020/07/20
littlefoxdiary.tistory.com
4. Measuring and Preventing Memorization Of Benchmarks

training dataset을 internet으로부터 가져왔기 때문에 우리 모델이 benchmark test set의 일부를 훈련했을 가능성도 존재한다.
따라서, detecting test contamination은 새로운 연구 분야로 제시된다. 이는 dataset의 크기가 커짐에 따라서 더 중요하게 다뤄질 문제가 된다.
GPT-2에서도 같은 문제에 대한 연구를 수행했는데, 이때는 training과 testing 시에 overlap이 있어도 큰 차이가 없었기 때문에 contamination data가 적어서 성능에 큰 영향을 미치지 않았다고 판단했다.
하지만 GPT-3는 GPT-2보다 훨씬 큰 모델이며 contamination 문제에 대한 위험성이 잠재적으로 더 높다.
- 그러나 pre-trained dataset이 워낙 방대하기 때문에 GPT-3 모델 조차 train dataset에 overfitting하지 못하므로 성능에 큰 영향을 주진 못했을 것이라 예상한다.

사전 학습 과정에서 test set이 유출된 것에 대한 영향을 평가하기 위해 ‘clean’ test set을 만들어 모델을 평가했다.
유출된 데이터 셋에 대해서 특히 더 잘했다는 증거는 없으므로, 큰 영향을 주지는 않았을 것으로 예상하지만 우리가 모르는 또 다른 문제점이 존재할 수는 있다.
다만, 모델이 pre-training을 통해 test set을 외워서 성능을 높이는 것은 아니라는 것을 확인한다.
5. Limitations
- GPT-3가 GPT-2에 비해 훨씬 좋은 성능을 보여주고 있지만, 여전히 text synthesis와 여러 NLP task에서 약한 모습을 보이고 있다.
- text synthesis : document 수준에서 의미가 반복되거나 긴 문장에 대해서 일관성을 잃는다거나 불연속한 문장이 발생하는 등의 문제
- 일반 물리학 상식을 잘 수행하지 못한다.
- In-context learning 능력이 특정 task들에 있어서 떨어지는 모습을 확인
- Structural & algorithmic limitations
- autoregressive 언어 모델에서만 연구
- bidirectional / denoising과 관련된 objective function은 고려하지 않는다.
- fundamental limitations
- 모든 token에 대해 동일한 weight를 적용하고 있으며, 이로 인해 중요한 부분들을 반영할 수 없음.
- self-supervised objective function을 사용하는 것은 토큰을 예측하는 것에만 중점을 두기 때문에 언어 시스템에서 적절한 action을 취하기 어렵다.
- poor sample efficiency
- 훈련 과정에서 인간은 몇 개의 예제나 instruction만 보고도 task를 수행할 수 있지만 언어 모델은 아직 그렇지 않다는 점
- ambiguity
- 추론 시에 새로운 task를 학습 ? vs 이미 훈련 과정에서 배운 task 중 하나를 인지해서 수행?
- inference를 수행하는 데에 있어서 expensive & inconvenient
- GPT-3 모델을 학습하는 것도 매우 expensive하며 추론 과정도 쉽지 않다.
- 실용성 부분에서 아직은 비효율적인 모델
- distillation으로 해결 가능하며, GPT-3는 task-agnostic model이므로 더 자유롭게 distillation 가능
- not easily interpretable, well-calibrated
- 해석 가능성이 떨어지며 새로운 input을 calibration하기 어렵다.
6. Broader Impacts
언어 모델인 GPT-3가 사이즈가 커지고 더 좋은 performance를 가지면서 유용한 면들도 주목 받지만 ‘유해성’을 가진 contents를 제작할 우려도 있다.
여기서는 ‘유해성’에 더 초점을 맞추며, 이는 많은 사람들이 해당 연구에 더 집중하길 바라는 마음에서이다.
Section 6에서 고의적으로 악용할 가능성, 그리고 여러가지 bias, fairness 등을 다루고 energy efficiency에 대해서도 다룰 예정이다.
이는 추후에 더 자세하게 다룰 예정.
Discussion
논문을 쭉 읽다 보면, 어떤 테크니컬한 느낌보다 어떤 방법으로 데이터와 모델 크기를 키웠더니 성능이 증가하더라. 와 같은 느낌을 받았다. 이 후에 소개할 FLAN 모델과도 비슷한 느낌을 받았는데, 결국 현재 AI의 핵심은 scaling law 안에서 움직이는 것 같은 느낌이었다.
그러나 인간은 GPT 모델과 같이 많은 데이터를 가지고 배우고 행동하는 것이 아니라고 생각하기 때문에, 딥러닝의 한계가 scaling law 그 자체인건 아닐까? 라는 짧은 생각이 들기도 했다.



