[논문 링크]
https://arxiv.org/pdf/2005.12872
이번 논문은 DETR 논문이다. 앞서 CoOp에서 언급했듯이, 여기선 "Learnable Query"를 활용한 아이디어를 소개하고 있다. 랩실 인턴을 할 때, 사수님께서 Abstract / Introduction을 잘 작성한 논문 + 연구에 흥미를 가질 수 있게, 장점이 잘 돋보이도록 작성한 논문이므로 다시 읽어보면서 추후 논문 쓸 때 참고해볼만큼 좋은 논문이라고 하셔서 조금 더 집중해서 보게 되었다. 실제로 이 분야에 대해서 지식이 충분하지 않음에도 읽고 이해하는 데에는 큰 문제가 없었던 것 같다. 더 깊게 이해하는 데에는 어려웠겠지만 어떤 아이디어, 어떤 방법론인지 이해하는 데에는 충분한 정도?
키워드는 다음과 같으며 가볍게 참고만 하자.
Keyword : DETR architecture, Hungarian Matching, Overall Training Loss, Learnable Object Query
그리고 논문 읽기에 앞서서 의미를 알아두면 좋은 것들도 가볍게 소개하고 시작하겠다.
- bipartite matching
- N개의 object 예측
- permutation을 진행하면서 적절한 object와 matching
- matching 후의 loss를 hungarian loss로 계산
- Hungarian loss는 optimal assignment (GT와 prediction을 잘 matching한 순서) 이 후에, GT와 prediction의 loss
- permutation-invariant
- sequence의 순서가 바뀌어 들어가도 괜찮다.
- Learnable Query
- CoOp / CLIP
- query를 배운다는 게 무엇인가?에 집중해서 읽어보기
Abstract
- Object detection을 direct set prediction problem으로 간주
- prior knowledge를 사용하지 않기 때문에, detection pipeline 간소화
- NMS / anchor generation
- DEtection TRansformer (DETR)을 제시
- Partite matching + Transformer encoder-decoder architecture
- object query는 고정하고 object간의 relation & prediction을 병렬로 추론 가능
- segmentation에도 generalization 가능
1. Introduction
Object detection = bounding box + category label의 set을 predict
- 즉, bounding box를 찾고 해당 bounding box가 어떤 category인지 찾는 것.
- 기존 방법들은 두 가지를 나눠서 진행 → localization + classification
⇒ direct set prediction approach 제안
machine translation이나 speech recognition 등에 많이 사용되었지만, object detection에는 아직 보편화되지 않았다.
이전에 시도들은 prior knowledge를 다른 형태로 추가하거나 challenge benchmarks에 대해서 strong baseline으로 충분한 성과가 있었음을 증명하지 못했다.
본 연구는 object detection (OD)를 하나의 prediction problem으로 간주하고 pipeline을 간소화 했다.
[Architecture]
- transformer 기반의 encoder-decoder architecture
- sequence prediction에 유용
- self-attention mechanism
- sequence 안에 있는 element 들 간의 pairwise interaction을 모델링
- removing duplicate prediction과 같은 set prediction의 specific constraints에 더 특화된 architecture 제공
- 여기서 removing duplicate prediction이란, 가장 좋은 prediction을 제외하고 나머지 카피본들을 제거한다는 의미이다.
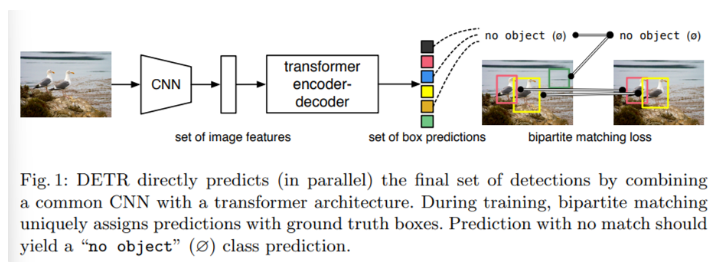
- 모든 object를 한번에 prediction하며 set loss function으로 end-to-end training
- set loss function : predicted object와 ground-truth object 간의 bipartite matching
- prior knowledge를 encoding하는 hand-designed components를 버리면서 pipeline을 단순하게 만들 수 있다.
- 대부분의 detection methods와 다르게, DETR은 customized layers가 필요 없다.
- 따라서 standard CNN과 transformer classes를 포함하고 있는 어떤 framework에서든 쉽게 만들 수 있다.
이전 방법들과 비교했을 때, 가장 중요한 DETR의 특징은 다음과 같다.
- bipartite matching loss
- predicted object를 ground-truth object에 하나씩 대응 → 이미지 속 각 객체를 정확하게 식별
- object를 예측하는 순서가 영향을 주지는 않기 때문에 parallel로 진행해도 괜찮음.
- 1번 sea, 2번 tiger, 3번 beach, … = 1번 beach, 2번 sea, 3번 tiger,…
- transformers with parallel decoding (non-autoregressive)
- 이전 연구들은 RNN을 활용한 autoregressive decoding에 초점
DETR을 제일 유명한 COCO dataset으로 평가하며 이는 Faster R-CNN baseline과 비교할 수 있을 만큼 좋은 performance를 보인다.
- Faster R-CNN은 많은 design iteration → improved performance
- DETR은 large object에서 Faster R-CNN보다 훨씬 더 좋은 성능
- but small object에서는 여전히 performance가 낮다.
- small object detection에 대한 future work 제시 (Faster R-CNN을 만들기 위해 FPN에 적용했던 방법들처럼)
DETR의 training setting은 standard object detector에 따라 여러 방면에서 다 다르다. 따라서 performance를 증명하는 데에 필요한 components들을 따로 제시한다. 또한, DETR은 segmentation과 같은 더 복잡한 task에도 확장이 가능하다.
2. Related Work
이 분야를 잘 모르기 때문에 related work도 읽어보았다.
- set prediction을 위한 bipartite matching loss
- transformer 기반의 encoder-decoder architectures
- parallel decoding
- object detection methods
2.1 Set Prediction
set prediction을 위한 표준 딥러닝 모델은 없다. 가장 기본적인 set prediction task는 multi-label classification인데, 이는 object detection에 적용할 수 있는 문제는 아니다.
이런 task에서 가장 첫 번째로 어려웠던 점은 ‘near-duplicates’를 피하는 것이다.
- 기존 방법론들은 post-processing (NMS)를 사용했으나, direct set prediction은 이런 방법을 사용하지 못하므로 예측된 elements들 사이의 모든 interaction을 구해서 redundancy (중복 제거)를 실행해야 한다.
- 하지만 fully connected network는 cost가 너무 커서 일반적으로 auto-regressive sequence (RNN)을 사용
- 모든 경우에서 prediction의 순서가 바뀌어도 invariant해야 한다. → permutation-invariance
- ground-truth와 prediction의 bipartite matching을 찾기 위해 Hungarian algorithm을 바탕으로 하는 loss를 사용
- permutation-invariance 보장
→ 하지만 DETR은 transformer with parallel decoding을 사용하며 왜 auto-regressive model 대신에 사용 했는지는 아래에서 설명
2.2 Transformers and Parallel Decoding
- transformers는 전체 input sequence로부터 information을 aggregate하는 neural network
- self-attention layer를 도입한 transformer는 전체 sequence로부터 정보를 aggregate하여 update → global computations & perfect memory
- 따라서 더 긴 sequence에 대해 RNNs보다 더 알맞음
Transformer는 처음에 auto-regressive model (sequence to sequence)에 사용되어 output token을 하나씩 생성했다.
하지만 이 방법은 inference cost가 너무 크기 때문에 여러 분야에서 parallel sequence generation이 개발되기 시작했다.
본 논문에서는 set prediction에 필요한 global computations을 수행할 수 있는 ability와 computational cost 사이의 적절한 trade-off를 위해 transformer와 parallel decoding을 결합한다.
2.3 Object detection
Two-stage detectors
- predict boxes (proposals)
- classification
이 방법들은 초기의 추측에 너무 크게 의존한다는 단점이 존재한다.
DETR은 hand-crated process를 삭제하고 detection process를 간단하게 만든다.
Set-based loss
초기 딥러닝 모델들은 bipartite matching을 convolutional, 혹은 fully-connected layers를 통해서만 모델링할 수 있었으며 hand-crated NMS를 통해 post-processing을 했다.
따라서 set-based loss를 사용하더라도 여전히 manually하게 처리해야만 했다.
3. The DETR model
2가지의 ingredient가 필수적이다.
- set prediction loss
- prediction과 ground-truth box 사이의 unique matching
- architecture
- 한 번의 과정으로 set of objects를 예측하고 그들의 relation을 modeling
- Figure 2에서 architecture 설명
3.1 Object detection set prediction loss
- DETR은 고정된 size, N개의 prediction을 inference
- decoder를 통해 한번에 prediction
- N은 일반적으로 image 내에 있는 object의 개수보다 훨씬 더 큰 숫자
- main difficult : ground truth에 대해서 prediction에 대한 score를 어떻게 구하지 ?
- optimal bipartite matching

- $y$ : ground-truth (GT)
- size N개까지 padding (공집합으로 padding하며 이는 object가 없다는 뜻)
- $\hat{y}$ : prediction
- $\sigma \in \mathfrak{G}_N$ : 가장 lowest cost로 N개의 elements들을 permutation
- permutation을 통해 N개의 elements들의 순서를 섞었을 때, 가장 loss가 작게 나온다는 집합 → 즉, matching한 결과에 대한 집합
- $\mathcal{L}_{match}$ : GT와 index $\sigma(i)$를 가지는 prediction 사이의 pair-wise matching cost
- 가장 optimal한 assignment는 Hungarian algorithm을 통해 효율적으로 계산된다.
또한, 여기서 matching cost는 class prediction과 GT와 prediction 사이의 similarity를 모두 고려한다.
- $y_i = (c_i,b_i)$
- $c_i$ : target class label
- $b_i \in [0,1]^4$ : GT box를 정의 (image size에 따른 height, width)
- $\hat{p}_{\sigma(i)}(c_i)$ : index $\sigma(i)$인 prediction의 class probability
- $\hat{b}_{\sigma(i)}$ : predicted box
따라서 전체 matching loss는 다음과 같이 정의된다.
$$ \mathcal{L}{match}(y_i,\hat{y}{\sigma(i)}) = -\mathbf{1}{\{c_i \neq \emptyset \}}\hat{p}{\sigma(i)}(c_i) + \mathbf{1}{\{c_i \neq \emptyset \}}\mathcal{L}{box}(b_i,\hat{b}_{\sigma(i)}) $$
matching을 찾는 과정은 modern detectors에서 GT object와 proposal or anchors를 matching하는 데에 사용되는 heuristic assignment rules과 같은 역할을 한다.
차이점은 duplicates없이 바로 set prediction을 수행하여 one-to-one matching이 된다는 점이다.

- Hungarian Loss
- 이전 step에서 matching된 모든 pair에 대한 loss
- 여기서 $\hat{\sigma}$는 가장 optimal한 assignment
- (2)는 cross-entropy 식과 비슷
- 여기서 indicator 함수를 사용한 이유는, no object일 때, classification은 수행해야 (no object이다!) object를 정확하게 찍을 수도 있지만, bounding box에 대해서는 loss를 계산할 필요가 없으므로 indicator 함수를 사용함.
Bounding box loss
(2)의 식에서 나오는 $\mathcal{L}_{box}$는 boundig box loss를 의미한다.
기존에 initial guess를 통해 bounding box prediction을 수행하는 방법들은 bounding box의 범위가 예측 범위에서 크게 벗어나지 않는다.
반면에 DETR은 initial guess가 없이 bounding box를 예측하므로 예측하는 값의 범주가 상대적으로 크다.
따라서, L1 loss만 사용하면 box 크기에 따라 서로 다른 범위의 loss를 가지게 되고, 이 문제를 해결하기 위해 L1 loss와 generalized IOU를 함께 사용하여 bounding box loss를 아래와 같이 정의한다.
$$ \mathcal{L}{box} = \lambda{iou}\mathcal{L}{iou}(b_i,\hat{b}{\sigma(i)}) + \lambda_{L1}||b_i - \hat{b}_{\sigma(i)}||_1 $$
- $\lambda$ : hyper-parameter
- $\mathcal{L}_{iou}$ : scale-invariant
3.2 DETR architecture

- 3가지의 main components
- CNN backbone
- 작은 feature representation을 추출
- encoder-decoder transformer
- simple feed forward network (FFN)
- CNN backbone
- DETR은 어느 딥러닝 framework에도 쉽게 적용할 수 있다.
- DETR은 Pytorch 상으로 50줄 미만으로도 충분히 구현할 수 있다.
Backbone
initial image $x_{img} \in \mathbb{R}^{3 \times H_0 \times W_0}$ → lower-resolution activation map $f \in \mathbb{R}^{C \times H \times W}$
Transformer encoder
- 1 x 1 convolution을 통해서 C → d의 dimension으로 낮춘 high-level activation map, f를 얻음
- 따라서 새로운 feature map은 $z_0 \in \mathbb{R}^{d \times H \times W}$으로 정의
- z_0은 transformer에 들어가기 위해서 하나의 sequence로 만들어지고, 따라서 dxHW의 크기를 가지게 됨.
- 각 encoder layer는 standard architecture
- multi-head self-attention module
- feed forward network (FFN)
- transformer architecture가 permutation-invariant하므로, 고정된 positional encoding을 수행
- 각 attention layer의 input에 추가
- 즉, 가장 먼저 attention을 수행할테니 input으로 들어가기 전 positional encoding을 추가한다는 뜻
- 각 attention layer의 input에 추가
Transformer decoder
decoder 또한 transformer의 standard architecture를 그대로 따름.
- multi-headed self-attention과 encoder-decoder attention mechanism을 사용하여 size d의 embedding을 총 N개 만듦.
- 한번에 하나의 element만 예측하는 다른 모델들과 달리, DETR은 각 decoder layer에서 parallel하게 N개의 objects를 decoding한다.
decoder도 permutation-invariant이므로 N개의 input embedding은 모두 다른 결과를 내기 위해서는 서로 다 달라야 한다.
이러한 input embedding은 학습 가능한 positional encoding이며, 이는 object query라고 부른다.
- encoder와 비슷하게, 각 attention layer의 input에 object query를 더해주는 방식으로 사용된다.
- N개의 object query는 decoder에 의해 output embedding으로 바뀐다.
- decoder 내에 있는 feed forward network를 통해 독립적으로 box coordinates와 class label을 decoding
- N개의 final prediction이 나옴
Prediction feed-forward networks (FFNs)
ReLU activation function을 가진 3-layer perceptron으로 final prediction이 계산된다.
FFN이 예측하는 것은 다음과 같다.
- bounding box
- normalized center coordinates
- height of box
- width of box
- class label using a softmax function
여기서 공집합은 standard object detection에서 “background”와 같다.

decoder가 query를 받고 object query를 받는다? → 모두 learnable query. positional encoding = learnable embedding query

Auxiliary decoding losses
decoder 학습 시에 auxiliary loss를 사용하는 것이 helpful 하다는 사실을 발견
각 decoder layer마다 FFN을 추가해서 auxiliary loss를 구해서 사용
- 모델이 각 class 별로 올바른 수의 object를 예측하도록 학습 시키는 데에 도움이 됨
- FFN은 서로 parameter를 공유
여기서 각 decoder layer마다 FFN을 추가할 때는, output embedding은 변하지 않으니까 중간 layer에도 최종 prediction에 대한 auxiliary loss를 추가해서 학습하면 더 도움이 됨. 처음에는 3번 쿼리에서 잘 잡고 뒤에서 32번 쿼리에서 잘 잡으면 implementation의 입장에서 더 좋을 것 같다는 의미로 해석했다.
4. Experiments
COCO dataset으로 Faster R-CNN과 DETR을 비교
- AP : Average Precision
- mAP : mean Average Precision
4.1 Comparison with Faster R-CNN

4.2 Ablations
transformer decoder에서 attention mechanisms은 다른 detection들의 feature representations 사이의 relation을 모델링하는 key components이다.
DETR의 다른 components가 어떻게 작용하고 final performance에 어떤 영향을 주는 지 탐구.
Number of encoder layers
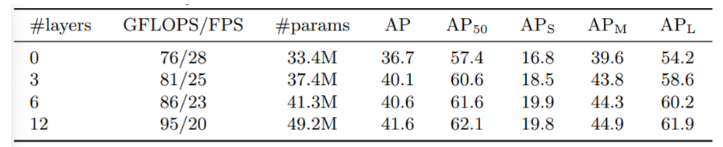
encoder가 없을 때, 전반적으로 3.9 p가 낮아지는 것을 확인할 수 있었고 large object에 대해서는 6.0AP가 떨어지는 것을 확인할 수 있다.
⇒ encoder가 global scene reasoing을 통해 object를 disentangle (분리)하는 작업을 수행한다고 가정
Number of decoder layers


- decoder layer를 추가 할수록 AP가 증가하는 모습
- 1개의 decoder만 사용할 경우, output끼리 cross-correlation을 연산하지 못하므로 duplicate prediction 발생
- 각 decoder output에 대한 연산이 위에 나와있음.
- 1개의 decoder만 사용할 경우, output끼리 cross-correlation을 연산하지 못하므로 duplicate prediction 발생
- encoder가 object를 background로부터 분리했기 때문에 decoder는 object의 경계 부분만 포착하면 됨
Conclusion
- Object detection을 set prediction task로 정의하여 prediction과 GT 사이의 1대1 matching
- near duplicate prediction을 감소 → end-to-end framework 제안
- encoder-decoder transformer를 활용
- pairwise interaction과 global reasoning
- Limitation
- small object에 대한 training, optimization, performance가 모두 어려움
- 1:1 matching을 통해 학습을 converge하는 데에 시간이 굉장히 오래 걸림.
Discussion
랩실 인턴 때, 사수님께서 이 논문을 읽어보라고 하셨다. 그렇게 해서 읽어본 논문인데 생각보다 잘 이해가 되고 새로운 분야를 또 탐구해볼 수 있는 기회였다. 현재는 detection과 관련하여 굉장히 좋은 성능을 보여주는 다른 모델들도 많다고 알고 있다. 그래서 이 논문이 가치가 없는 것처럼 느껴질 수도 있겠지만, AI 분야는 분야의 경계가 모호하다는 것이 또 다른 매력이라고 생각한다.
여기서 쓰인 방법론과 아이디어가 언제 어디서 신선하게 새롭게 이용될 수도 있기 때문에, 논문에 더 집중할 수 있는 동기가 된다. 얼른 연구 해보고 내가 설계한 실험들로 나의 가설을 입증하는 그런 시간을 가지고 싶다. . !