[논문 링크]
https://arxiv.org/pdf/2301.12597
BLIP 모델은 이제 Vision-Language Model에서 보편적으로 사용되고 있는 모델이 되었다. BLIP-1 논문도 있지만, 그 다음 버전 논문을 리뷰하는 이유는 이 논문 내용 안에 BLIP-1 내용도 포함되어 있기 때문이다.
키워드는 다음과 같으며, 가볍게 참고만 하자.
Keyword : BLIP-2 architecture, Training dataset, Self-Attention Masking in Q-Former, Overall Training loss (Stage 1 & 2)
- training dataset에서 어떤 점에 주목해야 하는지 ?
- 전체 training loss에서 stage 2의 training loss는 무엇인지?
- language modeling loss
- DETR의 decoder와 Q-Former는 거의 유사한 아키텍처
- Learnable query에서 유용한 정보를 extraction 해보자! 라는 느낌.
- Decoder와 Q-Former가 없어도 각각의 모델은 동작은 될텐데, 잘 되는지는 의문.
그리고 논문을 읽을 때 그냥 알고만 있으면 도움이 될 것 같은 단어도 일부 소개하겠다.
- off-the-shelf : 특별히 디자인하지 않고 바로 사용 가능한
- Bootstrapping : CapFilt method의 의미로 사용됨.
- LLava : instruction learning
Abstract
- vision-language model은 large-scale model의 end-to-end training때문에 pre-training cost가 점차 증가하고 있다.
- 따라서, BLIP-2를 제시하여 frozen pre-trained image encoder / LLM을 그대로 사용하여 vision-language pre-training을 bootstrap하는 방식을 제안한다.
- BLIP-2는 modality gap을 Querying Transformer로 채운다.
- 2가지의 stage로 학습을 진행
- first stage : bootstraps vision-language representation learning form a frozen image encoder
- second stage : bootstraps vision-to-language generative learning form a frozen language model
- 2가지의 stage로 학습을 진행
현존하는 방식보다 훨씬 적은 pre-training으로 SOTA를 달성
1. Introduction
다양한 vision-language model의 pre-training은 high computational cost가 요구된다.
따라서, Compute-efficient VL pre-training, BLIP-2를 제안.
- VLP를 위해 pre-trained unimodal models을 이용하려면 **‘cross-modal alignment’**가 필수이다.
- 기존 방식 (froze / flamingo, etc.)
- Pre-trained LLM + Vision model의 parameter를 frozen
- 그 후, 두 모델의 representation을 align하는 방식
- Image-to-text generation loss에만 의존
- BLIP-2
- parameter freeze는 동일하다.
- Q-Former라는 vision-language alignment 모델을 학습
- learnable query vectors의 집합
- LLM이 이해할 수 있는 visual features를 추출할 수 있다.
- 이를 통해 text와 더 연관 있는 visual representation을 학습할 수 있다.
- 기존 방식 (froze / flamingo, etc.)

[Key advantages]
- 효과적으로 frozen pre-trained image model & language model을 사용할 수 있다.
- modality gap은 2-stage로 학습한 Q-Former 모델을 통해 해결할 수 있다.

- LLM 덕분에 zero-shot image-to-text generation을 수행하는 prompt를 처리할 수 있다.
- visual knowledge reasoning, visual conversation과 같은 capability를 갖출 수 있다.
- Figure 4이미지를 이해하고 그에 대한 질의 응답을 할 수 있음.
- frozen unimodal models과 lightweight Q-Former를 사용하기 때문에, compute-efficient하다.
2. Related Work
2.1 End-to-end Vision-Language Pre-training
- vision-language pre-training은 multi-modal foundation models을 학습 시키는 데에 초점을 맞추고 있었으므로, downstream task에 따라 다른 architecture가 제시되었다.
- 또한,대부분의 VLP는 대규모 image-text pair dataset을 사용하여 end-to-end pre-training을 수행하므로, 모델의 사이즈가 커짐에 따라 computation cost도 극단적으로 커지는 것을 확인할 수 있었다.
- ⇒ LLM과 같은 end-to-end 모델들이 uni-modal pre-trained models을 사용하는 것이 조금 inflexible하다.
2.2 Modular Vision-Language Pre-training
- VLP (Vision-Language Pre-training)동안 off-the-shelf pre-trained models을 frozen한 상태로 사용하는 이전 연구들은 많았다.
- CLIP에서는 frozen image encoder를 사용
- 몇몇 방법들은 LLM의 knowledge를 사용하기 위해 language model을 freeze
- 하지만 이 방법들이 어려운 점은, text space와 visual features를 align하는 게 어려웠다는 점이다.
- Frozen finetunes an image encoder→ LLM으로 바로 prompt
- Flamingo는 cross-attention layer를 LLM에 삽입하여 visual features를 사용할 수 있게 만듦.
3. Method
3.1 Model Architecture

- Q-Former를 frozen image encoder와 froze LLM 사이의 gap을 이어주는 trainable module로 사용한다.
- 이미지에서 고정된 숫자의 output features를 추출하는데, 이는 image resolution과는 별개다.
- Q-Former는 figure 2에서 볼 수 있듯이, 같은 self-attention layer를 공유하는 2개의 transformer sub-module로 구성되어 있다.
- visual feature extraction을 위해 frozen image encoder와 상호작용하는 image transformer
- text encoder, decoder의 역할을 모두 수행하는 text transformer
- image transformer의 input으로써 learnable query embedding을 만든다.
- 각각의 query는 self-attention을 통해 interact
- frozen image features와는 cross-attention을 통해 interact
- 모든 transformer block에 포함되어 있음
- query는 추가적으로, 공유되어 있는 self-attention layer를 통해 text와도 interact
- downstream task에 따라서 query-text interaction을 조절하기 위해 다른 self-attention mask를 적용한다.
- Q-Former를 BERT base의 pre-trained weight로 initialize, cross-attention layers는 randomly initialize
- 188M parameters (Query는 model parameter로 간주)
- 32개의 query + 768 dimension (=hidden dim of the Q-Former)
- Z를 output query representation으로 사용 (32 x 768)
- 기존 이미지가 257 x 1024라는 점에서, bottleneck 구조가 형성
- query가 text와 더 연관 있는 visual information을 추출하도록 유도
3.2 Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
First stage
Q-Former를 frozen image encoder에 연결하고 image-text pair로 pre-training
이 때, Q-Former는 text information을 더 많이 가지고 있는 visual representation을 extract할 수 있도록 학습하는데, BLIP에서 영감을 받아 3개의 pre-training objectives를 optimize한다.
이들은 모두 같은 input format을 받으며 같은 model parameter를 공유한다.
각 objective는 query와 text 사이의 interaction을 조절하기 위한 각각의 attention masking strategy를 사용한다.
Image-Text Contrastive Learning (ITC)
ITC는 mutual information을 최소화 하는 것과 같이, image representation과 text representation을 align하는 것을 학습하는 게 목표이다.
이는 positive pair의 image-text similarity를 negative pairs와 비교함으로써 가능하다.
- image transformer로부터 나온 output query representation, Z와 text transformer로부터 나온 text representation, t를 align
- 이 때, t는 [CLS] token의 output embedding이다.
- Z가 여러 output embedding을 포함하고 있기 때문에 가장 먼저 각 query의 output과 t의 pairwise similarity를 계산한다.
- 여기서 Z가 여러 output embedding을 포함한다는 것은, output query representation에서 query가 1개가 아니라 여러 개이기 때문에 각 query에서 나온 output representation도 여러 개라는 뜻이다.
- 그리고 image-text similarity가 가장 높은 1개를 선택한다.
- 이 때, information leak을 방지하기 위해 text와 query가 서로 볼 수 없는 uni-modal self-attention mask를 사용한다.
- Figure 2의 맨 오른쪽 그림
- frozen image encoder 덕분에 end-to-end methods보다 GPU 1개당 더 많은 sample들을 fit할 수 있다.
- 그리고 나서 in-batch negatives를 사용한다.
Image-grounded Text Generation (ITG)
ITG loss는 Q-Former가 condition으로 주어진 input images를 바탕으로 text를 generation하도록 훈련 시킨다.
- Q-Former architecture가 image와 text 사이에 있으므로, frozen image encoder와 text token간의 직접적인 interaction은 불가능하다.
- 따라서, text generation을 위한 information은 query에 의해 1차 추출이 되어야 하며, 추출된 text token들은 self-attention layer를 거친다.
- 결국, query는 text에 대한 모든 정보를 capture할 수 있는 visual features들을 추출할 수 있게 된다.
- query-text interaction을 조절하기 위해 multi-modal causal self-attention mask를 사용한다.
- query는 서로 attention 가능하지만 text token과는 attention X
- 반면에 text token은 모든 query에 attention 가능하며 이전 text token과도 attention 가능
- causal이라고 부르는 이유가 이것 때문인 것 같음.
- 또한, 우리는 [CLS] token을 새로운 [DEC] token으로 대체할 수 있다.
- [DEC] token : decoding task에 signal을 보내는 가장 첫 번째 text token
Image-Text Matching (ITM)
image와 text representation의 fine-grained alignment를 학습 → binary classification task
즉, image-text pair가 positive인지 (match) negative인지 (unmatch)를 예측
- CLIP에서 image-text pair가 matching되면 해당 값들만 크게 하고 나머지 값들은 suppress하여 pre-training하고, inference 시에 positive이면 matching → predict class 방식이었던 것 같은데, 그 방법을 이용한건가? 이 부분에 대해선 자유롭게 이야기해주면 좋겠다.
Bi-directional self-attention mask를 활용 → text와 모든 query가 서로 attention이 가능
- output query embedding인 Z가 multi-modal information을 capture
- 각 output query embedding을 two-class linear classifier에 logit을 얻기 위해 태움.
- 모든 query에 대해 logit을 average → output matching score로 활용
- hard negative mining strategy를 적용 ← create informative negative pairs
3.3 Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
Second stage
Generative pre-training 단계에서, LLM의 generative language capability를 이용하기 위해 frozen LLM과 Q-Former를 연결한다.
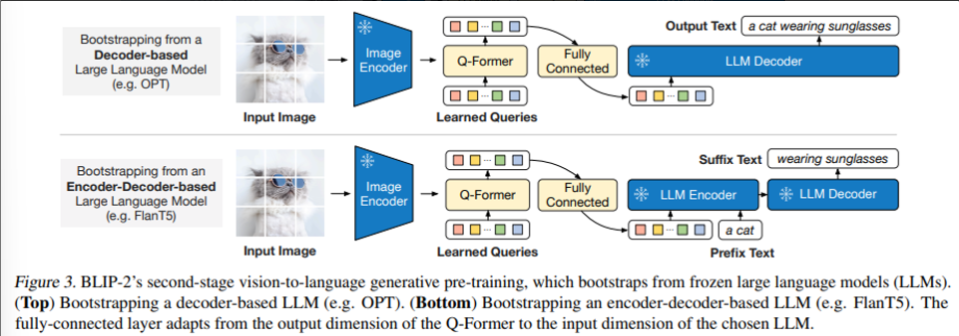
- Fully connected layer를 통해 output query embedding인 Z를 linear projection
- LLM의 text embedding과 동일한 dim
- projection된 query embedding은 input text embedding과 결합되어 soft visual prompt로써 활용된다.
- Q-Former에서 추출한 visual representation에 따라 LLM에 conditioning
⇒ 결국, Q-Former는 text와 더 연관 있는 visual information을 LLM에 제공하기 때문에, (image에서 text와 관련 없는 정보들은 빼고 제공) LLM이 alignment하는 데에 더 유용하고 따라서 더 효과적으로 정보를 처리할 수 있다.
2가지 type의 LLM 사용
- decoder-based LLMs
- Q-Former로부터 visual representation을 받음 → text 생성 → language modeling loss 계산
- encoder-decoder based LLMs
- prefix language modeling loss
- prefix text는 query와 함께 encoder의 input으로 들어감
- suffix text는 LLM’s decoder에 generation target으로써 사용됨
3.4 Model Pre-training
Pre-training data
총 129M images로 pre-training
- COCO
- Visual Genome
- CC3M
- CC12M
- SBU
- LAION400M
- 115M images
또한, CapFilt method를 적용하여 web image에 synthetic caption을 생성
- BLIP large captioning model을 사용하여 10개의 captions을 생성
- CLIP ViT-L/14 model로 계산한 image-text similarity를 기반으로 original web caption과 잘 맞는 synthetic caption을 ranking
- 각 이미지 당 top-2개의 captions을 유지한 상태에서 1개를 randomly sample해서 각 pre-training step에 사용.
여기서, CapFilt method란?
- Captioning and Filtering
- Captioner : web image에서 caption을 생성 → image에 맞는 text를 생성
- Filter : 생성된 image-text pair에서 noise가 많은 pair를 제거
- ITC / ITM
- noisy image-text pair에서 noise를 줄인 새로운 dataset을 구축
- 즉, captioner와 filter가 caption을 bootstrapping하면서 성능을 높이고 더욱 다양한 caption을 사용하여 이득을 본다.
- CLIP은 web crawling으로 모든 데이터를 그대로 끌고 와서 사용해서 noise가 심한 데이터를 그대로 사용해야 한다는 단점이 있었는데, Capfilt를 통해 corpus의 quality를 조금 더 향상시킬 수 있지 않았나?
Pre-trained image encoder and LLM
vision transformer models
- ViT-L/14 from CLIP
- ViT-g/14 from EVA-CLIP
- 여기서 ViT의 마지막 layer를 삭제하고 마지막에서 두 번째 layer의 output을 사용
- 성능이 조금 더 좋게 나옴.
- 이 부분이 살짝 이해가 안됐는데, 어떻게 마지막 layer를 삭제할 생각을 했을까? 라는 의문이 들긴 했었다.
- ViT의 architecture 특성 상, 마지막 layer는 generation에 대해서 추가 정보를 넣어야 하기 때문에 그 전 layer의 output이 더 image에 대한 representation을 잘할 수 있다는 가정이지 않을까? 라는 생각으로 이어졌고, 어떤 논문에서 ViT의 layer에 따른 역할을 확인하기 위해 ablation study를 진행한 것을 찾았다.
- 실험 결과는 마지막 layer에 대한 ablation study를 진행했을 때, downstream task에 대해서 성능이 엄청 하락된다는 것이었고, 결국 마지막 layer가 각각 task에 맞는 역할을 수행한다는 결론으로 도달했다. 따라서 representation은 그 전 layer까지만 사용하는 것이 보편적일 것이라는 가정이 성립된다.
(Optional)내가 이해한 Self-attention & masking 설명
만약에 32개의 query와 77개의 text embedding이 있다면, self-attention은 (32+77)개가 input으로 들어간다.
- text generation할 때는, image 기반으로 text를 생성해야 하기 때문에 생성하지 않은 text token들은 다 가려야 한다.
- image-text contrastive일 때는 각각의 representation을 잘 align해야 하므로, 같은 modality끼리만 볼 수 있도록 masking
- image-text matching은 서로 다 보고 align → masking 불 필요
4. Experiment

BLIP-2의 performance에 대한 overview table (table 1)
4.1 Instructed Zero-shot Image-to-Text Generation
BLIP-2는 LLM이 효과적으로 image를 이해할 수 있도록 만듬.
우리는 단순하게 text prompt 뒤에 visual prompt를 추가하여 LLM에 input을 넣으면 된다.
Figure 4는 zero-shot image-to-text capabilities의 넓은 범위에 대한 예제를 보여주고 있다.
- visual knowledge reasoning
- visual commonsense reasoning
- visual conversation
- personalized image-to-text generation
Zero-shot VQA
quantitative evaluation → zero-shot visual question answering
- OPT models
- Question: {} Answer:
- FlanT5 models
- Question: {} Short answer:

대부분의 task에서 SOTA에 준하는 성능을 보여주고 있다.

Q-Former를 통한 representation learning이 의미가 있었음을 알 수 있는 부분.
4.3 Visual Question Answering
LLM은 frozen한 채로, VQA data에 대해서 Q-Former를 학습
- fine-tuning할 때, open-ended answer generation loss로 fine-tune
- LLM이 Q-Former’s output과 question을 input으로 받고 answer를 답변으로.
※ question과 더 연관 있는 image feature를 추출하기 위해 condition Q-Former를 question에 추가로 사용.

- 그러면 Q-Former에서 query output embedding 뿐만 아니라 question까지 거친 representation이 나오는건가?
- 그리고 다시 question을 LLM에 입력?
- 이러면 image에서 question에 대한 정보를 고려해서 더 유의미한 text information을 추출할 수 있는건가? → 맞음!
5. Limitation
- 최근 LLM들은 in-context learning을 통해 few-shot이 가능함
- BLIP-2는 in-context VQA example을 LLM에 제공했을 때, VQA performance가 향상되지 않았음 → in-context learning이 안된다는 점.
- single image-text pair이기 때문에 향상되지 않았음을 지적
- image 1개에 여러 text (다양한 맥락에서 해석할 수 있도록)가 담긴 dataset 구축을 future work로 제시
- LLM의 부정확한 지식 전달, bias 등이 그대로 BLIP-2에 반영됨
- offensive language, propagating social bias, etc.
Discussion
확실히 VLM 쪽으로 넘어 오면서 더 다양한 접근 방법을 확인할 수 있게 되었다. VLM의 핵심은 이미지와 텍스트의 representation을 얼마나 잘 alignment할 수 있는지, 얼마나 2개를 적절하게 이해하는지가 중요하다고 생각하는데 여기서 Q-Former를 사용한 방법이 추후에 여러 논문에서 linear layer나 특정 adapter를 사용하여 다른 모달리티의 정보를 처리하는 아이디어로 이어지지 않았을까 생각한다. 물론 Q-Former가 그 아이디어에 영향을 받은 거일수도 있지만.. !
그리고 BLIP-2를 보면서 아직 LLM에 도달하기는 조금 어려워 보였다. 하지만 기술이 워낙 빠르게 발전하고 이 분야의 연구가 매일매일 새롭게 느껴지기 때문에 이 또한 극복되지 않을까..!