CausaLM 프로젝트 (2)
지난 포스팅에서 논문의 본격적인 내용에 들어가기 전까지의 내용들을 살펴보았다.
오늘은 3장인 model explanation을 다뤄보고자 한다.
3.1 Causal Inference and Language Representations

3개의 causal graph는 위에서 제시한 ‘형용사’와 ‘정치인’이라는 concept으로 만들어진 text들을 처리하는 과정이다.
- 맨 위의 그래프는 일반적인 데이터 생성 과정인 g를 의미한다. 2개의 concept이 X라는 text를 만들어내고 그에 따른 추후 과정을 의미한다.
- 2번째는 text 그 자체를 manipulating한 경우이다. 이 경우에는 Adjective가 생성 과정에 참여하지 않는데, 이로 인해 편향이 발생할 수 있다.
- 3번째는 본 연구의 approach이며, 생성 과정 g를 통해 text인 X를 생성한다. 이때, X는 실제 text가 아닌, text representation의 형태라는 것을 유념해야 한다.

j번째에 등장하는 C라는 concept으로 만든 text인 X를 파이라는 과정을 거쳐 text representation으로 만들고 f라는 classifier를 이용해 classification output을 만든 다음, Z벡터로 최종 class를 부여하는 과정을 거친다.
이렇게 과정을 놓고 보면 쉬워 보이지만, 여기서 중요한 개념은 바로 ‘Confounding’ 이다.
Causal inference에서 confounder은 예측한 label과 다른 변수들 모두에게 영향을 주는 변수를 의미한다.
위의 graph들을 보면, 현재 정치인이라는 concept은 X라는 결과와 adjective 라는 concept 모두에게 영향을 미친다.
⇒ 따라서 C_pf는 C_adj의 confounder이라고 할 수 있다.
만약, C_pf가 변경되어도 C_adj가 변경되지 않았다면, 우리는 C_adj와 C_pf가 서로 confound되지 않았다고 할 수 있다.
이 경우, 다음과 같은 수식으로 이해할 수 있다.
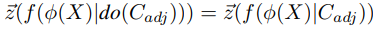
이 때, do-연산자는 특정 조건 하에 결과값이 어떻게 바뀌는 지를 나타내는, 즉 인과 관계를 명시적으로 표현하기 위한 개념이다. 따라서 여기서는 do(C_adj)는 C_adj를 변화시키는 외부 개입을 의미한다.
특정 개념 C의 존재에 영향을 받지 않는 counterfactual representation인 파이_c(X)를 생성하며, 이는 다음과 같은 식으로 설명될 수 있다.

3.2 The Textual Representation-based Average Treatment Effect (TReATE)
Causal effects를 측정할 때, 보통 average treatment effect를 가지고 판단한다.
Average treatment effect란, treatment group과 control group, 즉 특정 과정을 거친 treatment group과 아무것도 과정을 거치지 않은 control group 사이의 평균 변화를 의미한다.
본 연구는 do-연산자를 사용하여, 4가지의 방법으로 causal effect를 측정하는 방법을 정의한다.
- Average Treatment Effect (ATE)
- Causal Concept Effect (CaCE)
- Example-based Average Treatment Effect (EATE)
- Textual Representation-based Average Treatment Effect (TReATE)
3.3 Representation-Based Counterfactual Generation
Generating Synthetic Examples
counterfactual generation은 실제적인 텍스트를 생성하는 데에 많은 어려움이 있으며, 비용과 시간적인 측면에서도 어려움이 많다. 또한, counterfactual example을 만들었다고 하더라도 비교하는 과정에서 선택한 개념과 관련이 없는 모든 정보들을 가지고 있어야 하므로, 단순 비교보다 더 어려워질 수 있다.
따라서, 실제 text를 manipulating하는 것보다, textual representation에 intervention하는 것이 더 많은 counterfactual generation을 하지 않아도 되며 generation process의 품질에 의존하지 않아도 된다.
Interventions on Language Representation Models.
일반적인 contextual embedding model들은 3가지의 단계를 거친다.
- Pre-training
- Fine-tuning
- Supervised task training
여기서, 본 연구는 2번째 단계인 ‘Fine-tuning’에 집중했다.

- NSP (Next Sentence Presention)
- MLM (Masked Langauge Model)
- CC (Controlled Concept) : 추가적인 task를 삽입
- TC (Treated Concept objective) : MLM, NSP와 함께 추가적인 objective로 활용
위의 그림은 fine-tuning 과정을 설명하는 그림이다.
TC라는 과정을 추가했는데, 이는 adversarially (적대적) training을 진행하는 task이다. 즉, 처리한 concept의 effect를 ‘forget’하는 과정이다.
그리고 이 후, 처리된 concept이 forget되지 않고 여전히 ‘remember’되어 있는지를 확인하기 위해 CC라는 task를 추가했다. 만약 remember되어 있다면, 이는 잠재적인 confounder이 될 수 있기 때문이다.
그리고 위의 그림에서 추가적인 설명이 필요한 부분들이다.
- PRD , PLR : BERT 모델의 prediction head와 pooler head
- AVG - PLR : 다양한 모델 부분에서 정보를 집계하는 데 사용될 수 있는 평균 pooler head
- FC : Fully connected layer로, 입력 데이터를 변환하는 데 사용
- [MASK], NSP, MLM
그렇다면, 다시 한번 본 연구에서 우리가 사용한 ‘Intervention’에 대해 살펴보자. 가장 위에 있었던 figure에서 우리는 텍스트에 대한 형용사 영향을 살펴본다고 가정하자.
텍스트에 형용사가 있는지 여부가 분류 결정에 영향을 주는지 테스트한다면, 우리는 이를 위해서 테스트 세트의 각 예제에 대해서 ‘형용사가 포함되지 않은 동등한 예제를 생성’ 해야 한다. 이는 형용사를 포함하는 문장의 표현이 형용사가 제외된 동일한 문장의 표현과 일치해야 한다는 것을 의미하며, 이를 실행하기 위해 우리는 adversarially training을 진행하는 것이다.

우리는 위의 손실 함수를 추가해주었다.
- theta_BERT는 BERT의 모든 parameter들을 의미하며, 나머지는 각 objective에 맞는 parameter들이다.
- lamda : adversarial task의 상대적 weight를 조절하는 hyper-parameter이다.
- IMA TC head (추가) : 형용사를 masking → 어떤 토큰이 형용사인지 예측하는 작업을 말한다. 이들은 DANN (Gradient Reversal) 방법을 이용하여 구현한다.
- Gradient Reversal : 주어진 domain discriminator과 구별할 수 없는 common representation을 학습시킴으로써 domain간의 격차를 줄이는 것을 목표로 하는 도메인 변환 방법이다.
모델 설명에 관한 부분을 다루었다.
이 후, 4장에 나오는 data 부분은 생략하고 다음은 어떤 task와 experiment를 실험했는지, 그리고 어떤 결과가 나왔는 지에 대해서 포스팅하도록 하겠다.


