Naver Webtoon 베스트 댓글 프로젝트 - 최종
네이버웹툰 베스트 댓글 NLP 프로젝트 - 크롤링 (1)
Naver Webtoon 베스트 댓글 프로젝트 - 크롤링 (NLP) 자연어 처리 수업을 수강하면서, Final project로 '네이버 웹툰 베스트 댓글을 감성 분석 및 평점 분류' 라는 주제로 보고서를 만들었다. 자연어 처리 (
tjddms9376.tistory.com
NLP 프로젝트 2번째 보고서를 작성하려고 한다.
지난 시간에 어떤 식으로 네이버 웹툰에 있는 베스트 댓글들을 크롤링했는지 알아보았다.
이번에는 어떤 식으로 데이터를 활용했는 지에 대해 소개하고자 한다.
참고로, 이 프로젝트는 NLP를 처음 접한 대학생이 딥러닝, 머신러닝에 대한 실습을 전혀 해보지 않은 상태에서 진행한 단계라는 것을 유념해달라.
혹시 이 프로젝트를 보다가 개선했으면 좋겠다고 생각하는 피드백이 있다면 언제든지 댓글로 남겨주시면 감사하겠습니다.
모델 선정
Sentiment analysis를 진행하기 위한 model들을 여러가지 알아보았다.
- BERT
- XLNet
- LSTM
최종적으로 사용한 모델은 LSTM이며, BERT와 XLNet은 fine-tuning하는 방법에 대해서도 잘 몰랐고 크롤링한 데이터가 너무 많아서 colab pro로는 감당할 수 없는 모델이었기 때문에, 비교적 간단한 모델인 LSTM을 선정했다.
LSTM이란?
LSTM에 대한 설명은 프로젝트 소개를 위해 간단하게 설명하고 넘어가겠다. 자세한 내용은 논문 리뷰로 다룰 예정이다.
LSTM은 Long-Short Term Memory 의 약자로, RNN의 한 종류이다.
시퀀스 데이터를 모델링하고 RNN과 똑같은 체인 구조를 가지고 있지만, 반복 모듈에 대해서는 다른 구조를 가지고 있으며 3가지의 gate를 이용하여 정보의 흐름을 제어한다.

- Input Gate : 현재 입력에 대한 중요도를 결정
- Forget Gate : 이전 상태의 정보 중에 삭제할 정보를 선택
- Output Gate : 새로 계산된 현재 상태의 정보를 얼마나 전달할지 결정
Approach
1. 댓글 텍스트에서 특수 기호만 제거하도록 전처리를 진행
2. 전처리가 완료된 데이터를 train - test dataset으로 분할
3. Transformers에서 제공하는 pre-train 모델에 감성분석 레이블을 one-hot encoding
4. Fine tuning
5. 0 (부정) / 1 (중립) / 2 (긍정) 으로 sentiment classification을 수행하는 모델 완성
Evaluation method
성능을 평가하기 위해 우리는F1- Score를 활용했다.
F1-score란, precision (정밀도)와 recall (재현율)의 조화 평균값이다.
- Precision : positive로 예측한 경우 중에서 실제로 positive인 비율을 의미한다.
- 예측값이 얼마나 정확한 지를 판단하는 기준이라고 생각하면 된다.
- Recall : 실제 positive인 경우에서 올바르게 positive로 예측한 정도를 의미한다.
- 기존에 있었떤 정답을 얼마나 맞췄는 지를 의미한다.
F1-score는 데이터 분류 클래스가 균등하지 않을 때 많이 사용하므로, 감성 labeling이 지나치게 literalization이 되어 있는 우리 데이터 셋을 잘 판단할 수 있을 것이라 생각했다.
또한, TPR과 FPR을 이용하기도 했다.
- TPR (=recall)
- FPR : 실제 Negative 중에서 잘못 분류한 비율을 의미한다.

코드
실제로는 8개-10개정도, BERT와 XLNet을 fine-tuning해서 사용해보려고 했으나 기초가 잘 되어 있지 않아서 최대한 구글링을 통해 찾은 코드들을 활용했다.
가장 먼저 필요한 package들과 data를 불러왔다.
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
df = pd.read_excel('~filtering_classification.xlsx')
texts = df['댓글'].astype(str)
labels = df['전체 평점']그 이후, label mapping과 tokenization, padding, one-hot-encoding을 진행했다.
그리고 train-test data를 8:2로 분할하여 텍스트 데이터에 대한 전처리를 마무리했다.
# 감성 레이블 매핑 딕셔너리 생성
label_mapping = {0: 0, 1: 1, 2: 2}
# 감성 레이블 정수 변환
labels = [label_mapping[label] for label in labels]
# 텍스트를 정수 시퀀스로 변환
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
# 시퀀스 패딩
max_seq_len = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_seq_len)
# 감성 레이블 원-핫 인코딩
num_classes = len(label_mapping)
one_hot_labels = tf.keras.utils.to_categorical(labels, num_classes)
# 데이터 분할
train_ratio = 0.8
train_size = int(len(padded_sequences) * train_ratio)
x_train = padded_sequences[:train_size]
y_train = one_hot_labels[:train_size]
x_test = padded_sequences[train_size:]
y_test = one_hot_labels[train_size:]이제 LSTM 모델을 생성해보자.
# LSTM 모델 생성
embedding_dim = 100
hidden_units = 128
model = Sequential()
model.add(Embedding(len(tokenizer.word_index) + 1, embedding_dim, input_length=max_seq_len))
model.add(LSTM(hidden_units))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
# 모델 학습
epochs = 5
batch_size = 32
history = model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, validation_data=(x_test, y_test))loss function은 categorical crossentropy로 설정해주었다. 이제, 이를 바탕으로 model을 fit하면 다음과 같은 결과가 나온다.

마지막으로 예측 단계를 거쳤다.
# 테스트 데이터 로드
test_df = pd.read_excel('/content/drive/MyDrive/NLP/test_data_big.xlsx')
# 텍스트 전처리
test_sequences = tokenizer.texts_to_sequences(test_df['댓글'])
test_padded_sequences = pad_sequences(test_sequences, maxlen=max_seq_len)
# 예측
predictions = model.predict(test_padded_sequences)
# 예측 결과 DataFrame 생성
results_df = pd.DataFrame({'Text': test_df['댓글'], 'Predicted Label': [label_mapping[np.argmax(pred)] for pred in predictions]})
# 결과를 Excel 파일로 저장
results_df.to_excel('/content/drive/MyDrive/NLP/LSTM_big_결과.xlsx', index=False)Evaluation은 다음과 같이 진행했다.
# Macro average와 weighted average가 차이가 많이 나면 f1-score를 사용해야 한다.
from sklearn.metrics import classification_report
print(classification_report(actual_values, predicted_values))
##############################################################
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
# 혼동 행렬 계산
cm = confusion_matrix(actual_values, predicted_values)
# TPR 계산
tpr = cm[1, 1] / (cm[1, 1] + cm[1, 0])
# FPR 계산
fpr = cm[0, 1] / (cm[0, 1] + cm[0, 0])
# 결과 출력
print("TPR (True Positive Rate):", tpr)
print("FPR (False Positive Rate):", fpr)

macro average와 weighted average를 비교해서 차이가 크게 나오는 것을 확인하고 F1-score를 적용했다.
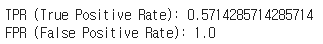

FPR값이 1.0이 나온 것부터, class 0과 class 1의 F1-score가 굉장히 낮게 나왔다. 실제 예측한 파일을 살펴보았을 때도,

보이는 것처럼 1에 대한 예측은 거의 맞춘 적이 없다.
아쉬운 점 및 개선점
위와 같은 결과가 나온 이유는 생각보다 많은 것 같다.
- 텍스트 전처리의 문제
- LSTM의 fine-tuning (parameter 조정에 대한 지식이 거의 없었으므로, 가장 기본적인 모델 구조를 그대로 사용한 점
- 데이터 불균형
- 이 부분은 특히 민감한데, label이 2인 데이터 수가 전체의 80%인 점이 문제였던 것 같다.
- test-train 데이터를 나눌 때도 동일한 비율로 나눠서 진행을 했다면, 더 좋은 결과를 얻었을 것 같은데 그 부분이 많이 아쉬웠다.
- Epoch의 수가 지나치게 적었던 점
- 학습 데이터의 수가 지나치게 많았던 점
나열하자면 더 나올 것 같지만, 크게 생각했던 아쉬운 점들은 위와 같다.
비록 만족할 만한 결과를 내지 못했지만, 처음으로 혼자서 진행해본 프로젝트였고 생각보다 이 과정에서 많은 것들을 배울 수 있었다. NLP 분야에 처음 관심을 가지게 된 계기가 되기도 했고, 텍스트를 다루다 보니 내가 생각하는 결과와 비슷하게 나올 때, 다른 분야보다 더 신기하게 다가왔던 것 같다.
정말 AI가 사람과 대화할 수 있다는 것을 실감하면서, 해당 프로젝트를 통해 NLP 분야에 더 관심을 가지게 되었다.
출처 : LSTM 그림 (http://www.incodom.kr/LSTM)
'프로젝트 > 네이버 웹툰 베스트 댓글 감성분석' 카테고리의 다른 글
| 네이버웹툰 베스트 댓글 NLP 프로젝트 - 크롤링 (1) (0) | 2023.08.22 |
|---|
